大多数APP里面返回的是json格式数据,或者一堆加密过的数据 。这里以超级课程表APP为例,抓取超级课程表里用户发的话题。
1、抓取APP数据包
方法详细可以参考这篇博文:Fiddler如何抓取手机APP数据包
得到超级课程表登录的地址:http://120.55.151.61/V2/StudentSkip/loginCheckV4.action
表单:

表单中包括了用户名和密码,当然都是加密过了的,还有一个设备信息,直接post过去就是。
另外必须加header,一开始我没有加header得到的是登录错误,所以要带上header信息。
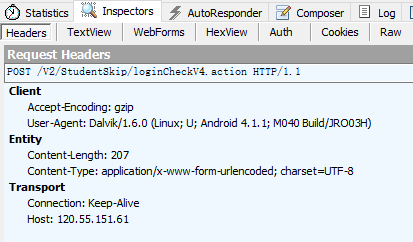
2、登录
登录代码:
import urllib2
from cookielib import CookieJar
loginUrl = 'http://120.55.151.61/V2/StudentSkip/loginCheckV4.action'
headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Dalvik/1.6.0 (Linux; U; Android 4.1.1; M040 Build/JRO03H)',
'Host': '120.55.151.61',
'Connection': 'Keep-Alive',
'Accept-Encoding': 'gzip',
'Content-Length': '207',
}
loginData = 'phoneBrand=Meizu&platform=1&deviceCode=868033014919494&account=FCF030E1F2F6341C1C93BE5BBC422A3D&phoneVersion=16&password=A55B48BB75C79200379D82A18C5F47D6&channel=MXMarket&phoneModel=M040&versionNumber=7.2.1&'
cookieJar = CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookieJar))
req = urllib2.Request(loginUrl, loginData, headers)
loginResult = opener.open(req).read()
print loginResult登录成功 会返回一串账号信息的json数据

和抓包时返回数据一样,证明登录成功
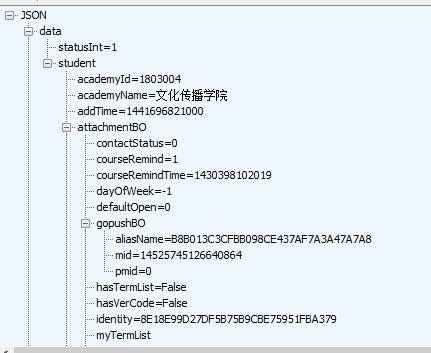
3、抓取数据
用同样方法得到话题的url和post参数
做法就和模拟登录网站一样。详见:Python爬虫模拟登录带验证码网站
下见最终代码,有主页获取和下拉加载更新。可以无限加载话题内容。
#!/usr/local/bin/python2.7
# -*- coding: utf8 -*-
"""
超级课程表话题抓取
"""
import urllib2
from cookielib import CookieJar
import json
''' 读Json数据 '''
def fetch_data(json_data):
data = json_data['data']
timestampLong = data['timestampLong']
messageBO = data['messageBOs']
topicList = []
for each in messageBO:
topicDict = {}
if each.get('content', False):
topicDict['content'] = each['content']
topicDict['schoolName'] = each['schoolName']
topicDict['messageId'] = each['messageId']
topicDict['gender'] = each['studentBO']['gender']
topicDict['time'] = each['issueTime']
print each['schoolName'],each['content']
topicList.append(topicDict)
return timestampLong, topicList
''' 加载更多 '''
def load(timestamp, headers, url):
headers['Content-Length'] = '159'
loadData = 'timestamp=%s&phoneBrand=Meizu&platform=1&genderType=-1&topicId=19&phoneVersion=16&selectType=3&channel=MXMarket&phoneModel=M040&versionNumber=7.2.1&' % timestamp
req = urllib2.Request(url, loadData, headers)
loadResult = opener.open(req).read()
loginStatus = json.loads(loadResult).get('status', False)
if loginStatus == 1:
print 'load successful!'
timestamp, topicList = fetch_data(json.loads(loadResult))
load(timestamp, headers, url)
else:
print 'load fail'
print loadResult
return False
loginUrl = 'http://120.55.151.61/V2/StudentSkip/loginCheckV4.action'
topicUrl = 'http://120.55.151.61/V2/Treehole/Message/getMessageByTopicIdV3.action'
headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Dalvik/1.6.0 (Linux; U; Android 4.1.1; M040 Build/JRO03H)',
'Host': '120.55.151.61',
'Connection': 'Keep-Alive',
'Accept-Encoding': 'gzip',
'Content-Length': '207',
}
''' ---登录部分--- '''
loginData = 'phoneBrand=Meizu&platform=1&deviceCode=868033014919494&account=FCF030E1F2F6341C1C93BE5BBC422A3D&phoneVersion=16&password=A55B48BB75C79200379D82A18C5F47D6&channel=MXMarket&phoneModel=M040&versionNumber=7.2.1&'
cookieJar = CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookieJar))
req = urllib2.Request(loginUrl, loginData, headers)
loginResult = opener.open(req).read()
loginStatus = json.loads(loginResult).get('data', False)
if loginResult:
print 'login successful!'
else:
print 'login fail'
print loginResult
''' ---获取话题--- '''
topicData = 'timestamp=0&phoneBrand=Meizu&platform=1&genderType=-1&topicId=19&phoneVersion=16&selectType=3&channel=MXMarket&phoneModel=M040&versionNumber=7.2.1&'
headers['Content-Length'] = '147'
topicRequest = urllib2.Request(topicUrl, topicData, headers)
topicHtml = opener.open(topicRequest).read()
topicJson = json.loads(topicHtml)
topicStatus = topicJson.get('status', False)
print topicJson
if topicStatus == 1:
print 'fetch topic success!'
timestamp, topicList = fetch_data(topicJson)
load(timestamp, headers, topicUrl)结果:
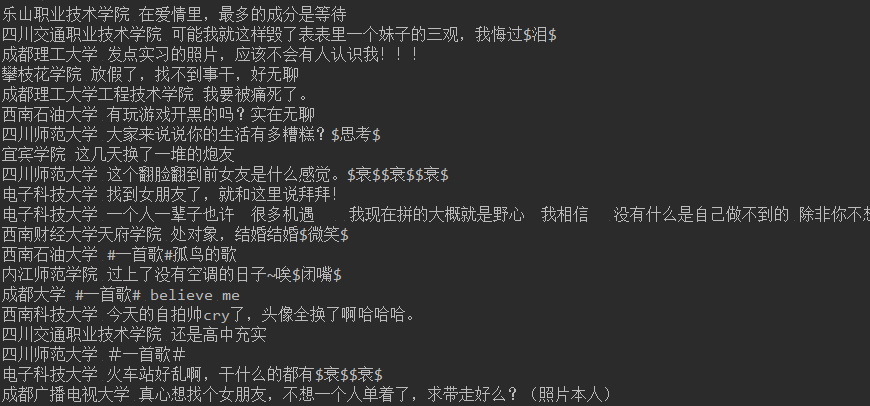
关键字词:
相关文章
- python 经常报错'module' object has no attribute 'X509_up_ref'
- python安装cv2 无法安装
- Python来识别字符串所属语言类型(langid 、langdetect)
- Python3 字典的复制与修改
- Python3 print 不换行打印教程
- Python3 bytes to string 字节码转字符串
- Scrapy Proxy Python下爬虫使用代理
- Scrapy 爬虫入门 内建设置参考 Python爬虫教程实战
- Scrapy 爬虫入门 Items 与 Item Pipeline Python爬虫教程实战
- Scrapy 爬虫入门 Spider 与 Selectors (选择器) Python爬虫教程实战


