
工欲善其事,必先利其器, 上一篇文章介绍了 Scrapy 入门示例 ,接下来介绍几款工具! Scrapy 支持使用xpath,css等来解析抓取的页面,如果对xpath不了解也不要紧, 神器一浏览器插件: Xpath 辅助工...

1. 创建项目 : 这里面使用一个在建网站 (456dev.com) 作为演示 使用 startproject 命令来创建一个项目 : Scrapystartprojectdemo 切换目录 : cddemo 用 genspider 命令建立一个通用 spider 模型 : Scrapygenspi...

判断文件是否存在: importosfilepath=test_file_not_existsprintos.path.isfile(filepath) 输出 True (存在)或 False(不存在) 判断是否是快捷方式: printos.path.islink(filepath) 输出 True (是)或 False(否) 判断目录是否...

Selenium是一个非常强大的web测试框架,有时候我们也会用它来写爬虫. 在使用过程中可能会遇到一些特殊的网页需要使用代理服务才能访问,比如: 下面通过一个简单的示例演示下怎么给w...
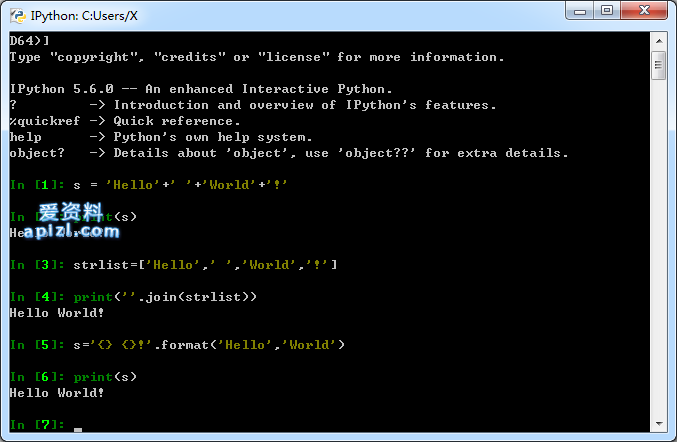
python拼接字符串一般有以下几种方法: ①直接通过(+)操作符拼接 s=Hello++World+!print(s) 输出结果: Hello World! 使用这种方式进行字符串连接的操作效率低下,因为python中使用 + 拼接两个...

在cmd下执行python循环怎么才能停止呢? 循环当遇到跳出条件就会停止了, 如果没有跳循环条件,像这种简单的循环代码示例: whileTrue:printapizl 像这样的没有退出循环条件的代码,只能强制停...

Python在开发过程中有时需要借助命令行程序来完成一些任务,这时就需要处理Python与命令行间的交互操作, 下面介绍一种比较简单的方法,通过调用命令行执行任务并获取执行结果: fromsu...

安装 requests 模块 #Python2.x版本pipinstallrequests#Python3.x版本pipinstallrequests2 GET请求 importrequests#这是一个错误一演示#通过Get请求方式获取源码response=requests.get( 当你执行上面的代码,你会得到...
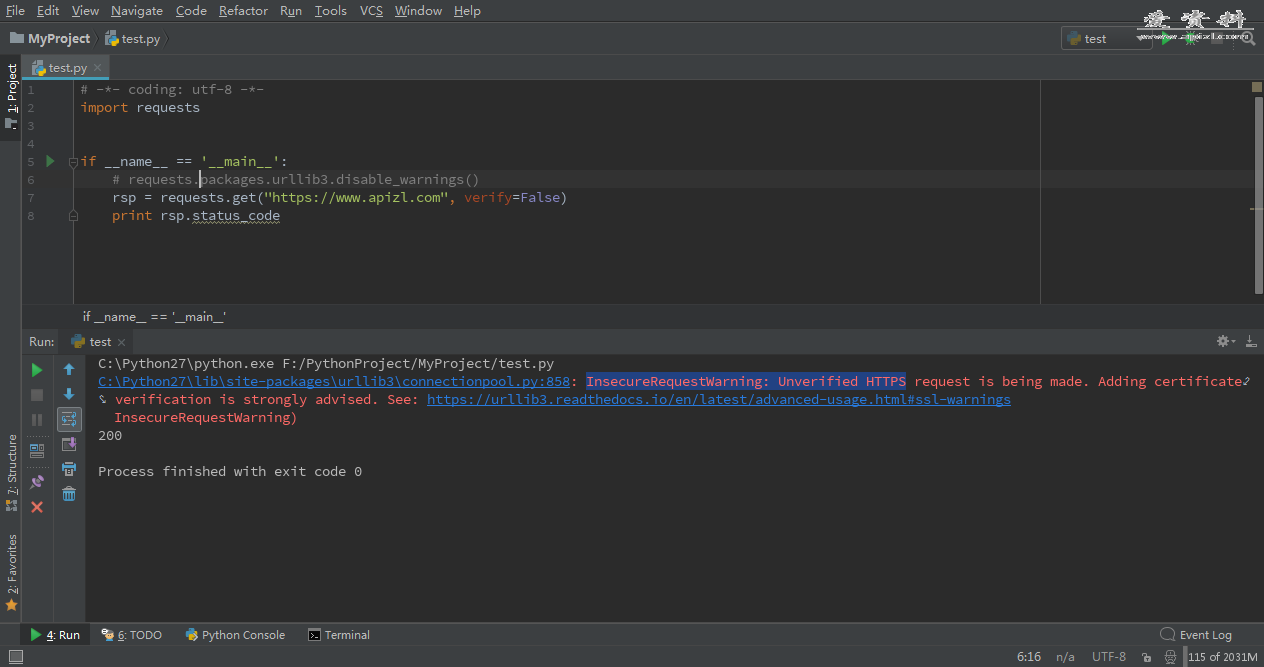
Python在使用requests访问HTTPS网站时,如果关闭了证书验证,就得输出一句警告日志: C:\Python27\lib\site-packages\urllib3\connectionpool.py:858:InsecureRequestWarning:UnverifiedHTTPSrequestisbeingmade.Addingcertificateve...
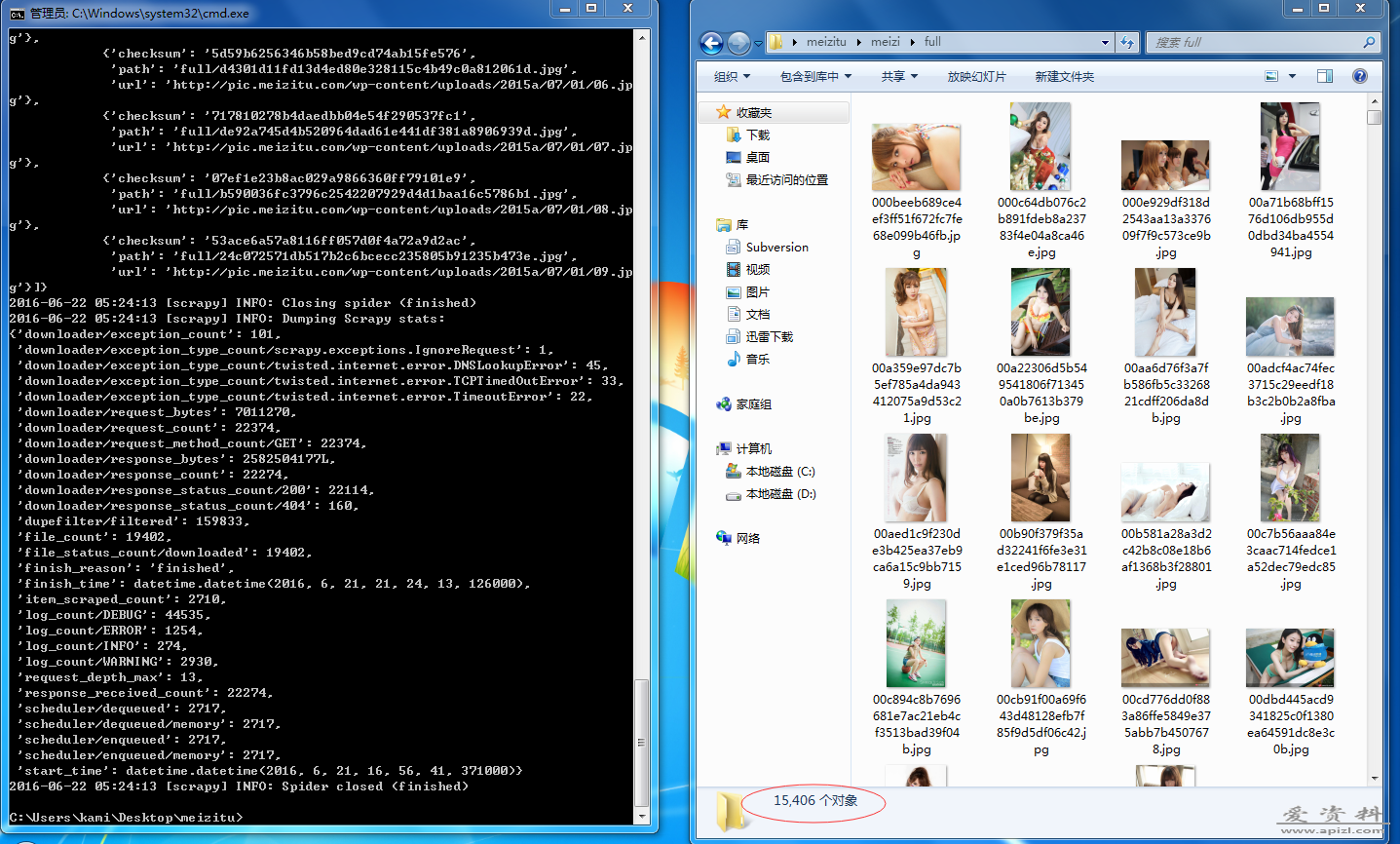
Python使用Scrapy 来抓取网页图片非常简单. Scrapy为下载item中包含的文件(比如在爬取到产品时,同时也想保存对应的图片)提供了一个可重用的 item pipelines . 这些pipeline有些共同的方法和结...